Introduction à Linux
1.Qu'est-ce que Linux?
Linux est un système d'exploitation qui fait partie de la grande famille Unix. En effet, Unix existe sous plusieurs saveurs dont Solaris de la compagnie Sun Microsystems, HP-UX de la compagnie Hewlett-Packard, AIX de la compagnie IBM, et évidemment Linux. Le noyau de Linux a été écrit par Linus Torvald, un étudiant finlandais, qui désirait créer une version d'Unix gratuite. Au début, il a écrit ce système d'exploitation comme un passe-temps. En effet, c'est en 1991 qu'il débute ce projet et il sort la version 0.02. Par la suite, en 1994, la version 1.0 du noyau ("kernel") est rendue disponible à la communauté Internet et plusieurs personnes transmettent à Linus Torvald des modifications à apporter à son système Unix. C'est durant cette période que Linux commence à faire parler de lui mais sans être pris au sérieux par les grandes corporations. Aujourd'hui, Linux est un système d'exploitation qui peut se comparer à Windows. En effet, on y a intégré des logiciels comme Samba pour qu'une machine Linux puisse parler avec un serveur Windows ou même être un serveur de fichiers et d'impression ! Aussi, on commence à voir apparaître une suite "Office" permettant de faire du traitement de texte, du chiffrier électronique, etc. Pour en savoir plus sur Linux, vous pouvez consulter le site Web du département d'informatique, au URL suivant :
http://linux.ift.ulaval.ca/
2.Entrée en ligne
Dans le cadre du cours "Implantation d'un site Internet", les exercices et les travaux devront être réalisés sur Linux. Dans les laboratoires du département d'informatique, vous avez la possibilité de démarrer un poste de travail soit en Windows ou soit en Linux. Lorsque vous arrivez dans le laboratoire, soit que le poste sera déjà en Linux, ou bien il sera en Windows. S'il est en Windows, vous devrez redémarrer le poste et un menu vous demandera si vous voulez démarrer en Windows ou en Linux. Vous devrez choisir Linux.
Lorsque le poste sera démarré, vous aurez la fenêtre suivante :
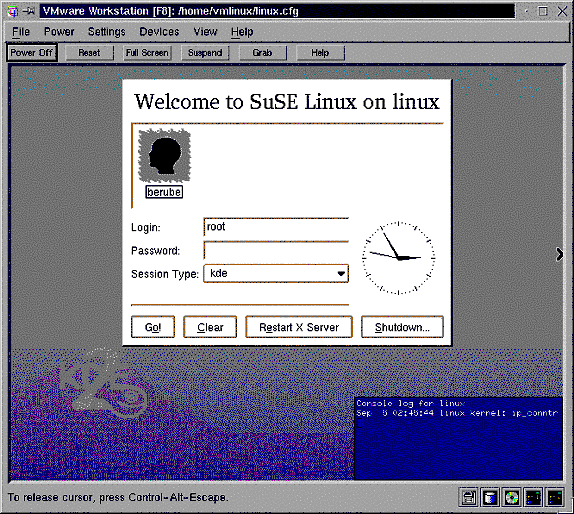
Vous saisissez votre code d'accès (identifiant unique) ainsi que votre mot de passe. Vous entrez alors dans votre compte.
3.Interfaces graphiques
Il existe 2 interfaces graphiques populaires sur Linux, soient KDE et GNOME. Par défaut, c'est l'interface KDE qui est installée sur le réseau du département d'informatique. Cette interface ressemble à celle de Windows avec une barre de menu dans le bas de l'écran. Lorsque vous entrez en ligne, vous aurez (à moins que vous n'ayez modifié votre environnement) la fenêtre suivante:
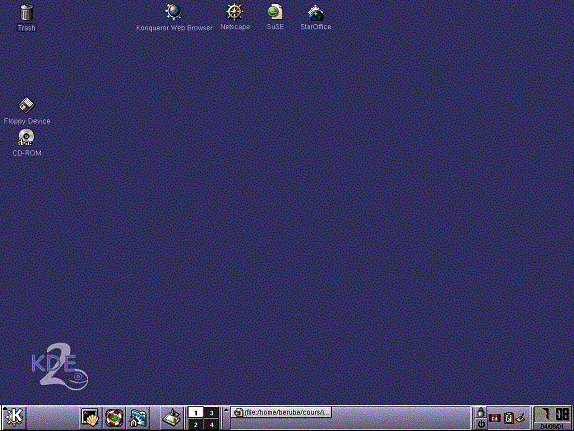
Une des caractéristiques de KDE et GNOME, c'est la notion de bureau de travail ("Desktop") virtuel. En effet, dans la barre de tâches, on y retrouve ces bureaux. Donc si l.'on veut passer d'un bureau à l'autre, il suffit de cliquer sur l'icône correspondante. Ceci est utile lorsque l'on doit travailler, par exemple, sur plus d'un projet à la fois. Dans le cas de KDE, on peut avoir jusqu'à 16 bureaux différents. Pour accéder à la configuration de la barre de tâches, on clique sur celle-ci dans un endroit où il n'y a pas d'icônes avec le bouton de droite de la souris. On choisit alors Settings... et un panneau de configuration apparaît. Il permet entre autres de déterminer l'emplacement de la barre de tâches. On peut aussi définir des nouveaux bureaux ("Desktop") virtuels en cliquant sur le bouton de droite de la souris dans l'une des icônes d'un bureau de travail virtuel et en choisissant Preferences....
Pour personnaliser son environnement dans KDE, on peut utiliser le KDE Control Center. On y accède en cliquant, avec le bouton de droite de la souris, sur l' icône K qui se trouve à gauche de la barre de tâches et en choisissant Control Center.
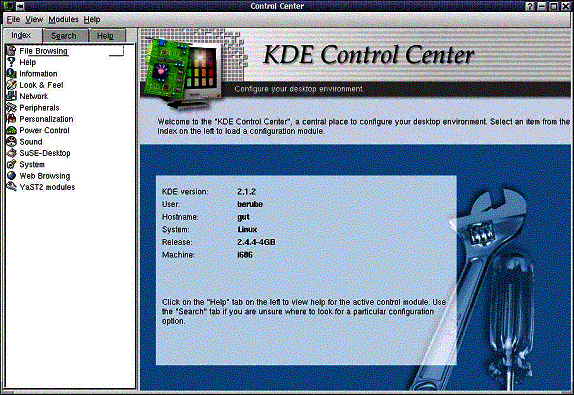
Il est donc possible, à partir de cet utilitaire, de configurer l'environnement de KDE. Sans entrer dans les détails et voir l'ensemble des possibilités, voici un tour d'horizon des différentes icônes que l'on peut voir dans la fenêtre de gauche:
·
File Browsing
·
Help
·
Information
·
Look & Feel
·
Network
·
Peripherals
·
Personalization
·
Power Control
·
Sound
·
SuSE-Desktop
·
System
·
Web Browsing
·
YaST
modules
Pour certaines options, il faut avoir les privilèges de root pour apporter des modifications. Les options que vous risquez de vouloir modifier se retrouvent dans Look & Feel et Personalization. Dans Look & Feel, on peut modifier l'arrière-plan du bureau de travail, la couleur du système de fenêtrage, les polices de caractères, etc. Dans Personalization, on peut définir la langue associée au clavier. Bref, c'est un utilitaire à connaître pour pouvoir personnaliser son environnement de travail.
4.Utilitaires
Il existe une foule d'utilitaires avec KDE. Sans en faire une liste exhaustive, quelques-uns méritent d'être vus.
·
Process
management
Cet utilitaire permet de voir l'ensemble des processus Unix qui s'exécutent. Il permet aussi d'arrêter des processus sans utiliser la commande Unix kill.
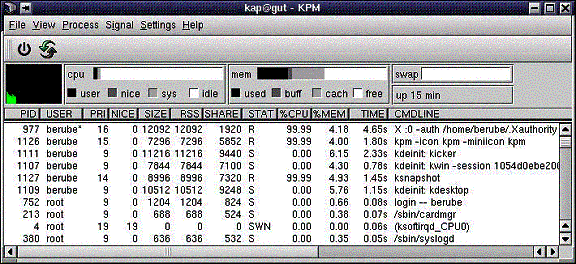
On peut démarrer cette application en cliquant sur l'icône K et en choisissant System et Process management. On reviendra sur la signification de chacun des champs un peu plus loin dans ce document.
·
Text
Editor
Dans la réalisation de vos travaux ainsi que pour les exercices, vous devrez utiliser un éditeur de texte. Pour démarrer l'éditeur Text Editor, on clique sur l'icône K, dans la barres de menu, et on va dans Editors.
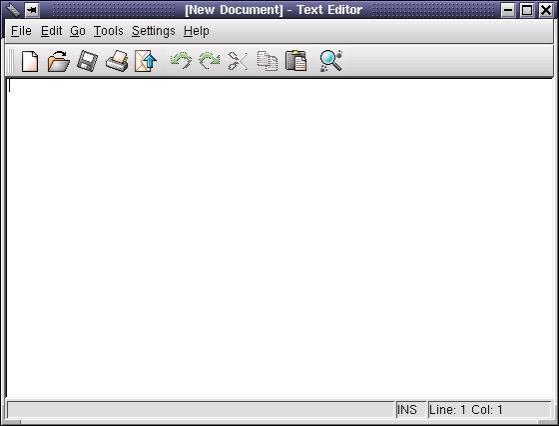
C'est un éditeur simple et facile à utiliser. Si vous désirez utiliser un vrai traitement de texte, KOffice est installé sur les postes de travail. On y accède par l'icône K et on choisit Office.
·
Ksnapshot
L'utilitaire KSnapshot permet de faire une "photo" d'une fenêtre. Il peut être utile si vous désirez inclure des écrans de saisie que vous aurez à créer dans vos travaux. Cet utilitaire permet de sauvegarder les images dans différents formats, dont GIF et JPEG.
Pour démarrer cette application, on clique sur l'icône K, et on choisit SuSE, puis on va dans Graphic, Graphics et on choisit ksnapshot. Vous verrez la fenêtre suivante apparaître:
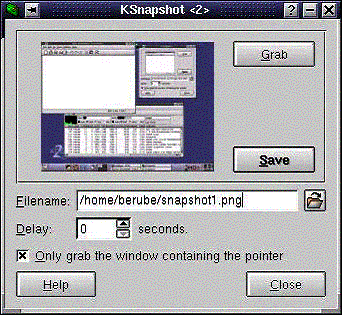
Si l'on veut que l'utilitaire saisisse une fenêtre précise, on activera l'option Only grab the window containing the cursor. Aussi, on doit fixer un délai d'au moins 1 à 5 secondes (Delay). On va cliquer sur Grab et la fenêtre de KSnapshot va disparaître quelques secondes. On va alors cliquer dans la fenêtre que l'on veut avoir une image. Lorsque c'est fait, la fenêtre KSnapshot revient en avant-plan. On verra aussitôt apparaître une image dans le coin supérieur droit de KSnapshot indiquant que l'image a bien été prise en "photo". On peut aussi utiliser Image Viewer dans Graphics pour la visualiser. Il suffit de choisir le format d'image à sauvegarder et un nom de fichier. On fait alors Save et celle-ci est alors sauvegardée.
·
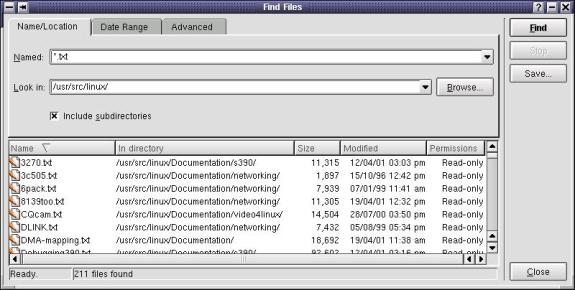
Find
Files
Cet utilitaire vous permet de rechercher des fichiers ou des répertoires. On peut même rechercher une chaîne de caractères dans le contenu des fichiers recherchés. Pour accéder à cet utilitaire, on clique sur l'icône K et l'on choisit Find Files. Lorsque la fenêtre ouvre, on peut alors entrer, par exemple, *.txt pour trouver tous les fichiers ayant pour extension .txt. On clique alors sur l'icône Find. La recherche s'amorce et dans le bas de la fenêtre, on retrouvera tous les fichiers ayant une extension .txt.
Si on veut rechercher, par exemple, la chaîne de caractères "caractères" dans les fichiers ayant pour extension .txt, on clique sur l'onglet Advanced et l'on peut alors entrer la chaîne dans le champ Containing Text. On clique sur l'icône Find, et l'on obtient la liste des fichiers correspondants.
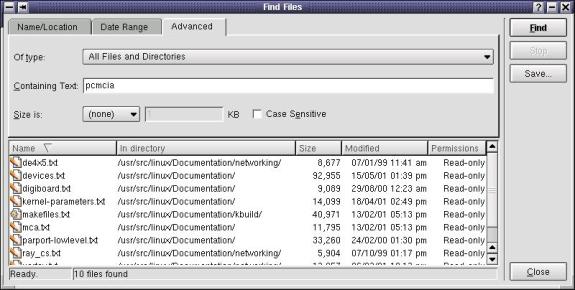
·
Konqueror
Cet utilitaire permet de naviguer dans vos répertoires et dans le système. Pour l'utiliser, on clique sur l'icône K et l'on choisit Home Directory. Il permet de faire plusieurs choses dont changer la permission d'un fichier ou d'un répertoire, modifier l'affichage, etc. Si l'on veut obtenir de l'information sur un fichier ou un répertoire, on clique sur ce fichier avec le bouton de droite et une fenêtre s'ouvre avec les 3 onglets suivants: General et Permissions. General permet de connaître le type de fichier, l'endroit où il se trouve, la dimension ainsi que les dates de modification et de consultation.
Il est donc possible de gérer des fichiers sans avoir à connaître toutes les commandes Unix.
·
Terminal
Cette utilitaire permet de d'accèder à Linux en mode commande. On verra plus bas quelques commandes Linux et pour les exécuter, on doit utiliser un "terminal". Pour l'utiliser, on clique sur l'icône K et l'on choisit System dans lequel on retrouve Terminal. La fenêtre suivante apparaît:
Il suffit d'entrer les commandes Linux à
l'invite ift20327@crimson:~
>.
·
Change
Password
Si l'on veut changer son mot de passe, on clique sur l'icône K, et l'on choisit Utilities dans lequel on retrouve Change Password.
On doit entrer son mot de passe actuel et ensuite deux fois le nouveau mot de passe.
Ceci fait donc un tour d'horizon de quelques utilitaires graphiques qui peuvent êtres utilisés dans KDE. Vous êtes invité(e)s à vous familiariser avec ces outils car ceci facilitera la vie pour la réalisation de vos travaux qui devront être fait sur Linux.
5.Coquille ("shell") Bash
Il est possible sous Linux d'exécuter des commandes en mode ligne. Pour pouvoir le faire, on doit utiliser une coquille, plus communément appelée "shell". Sur un système Linux, il existe quelques coquilles dont voici une liste:
Ø
ash
Ø
bash
Ø
tcsh
En plus de permettre l'exécution de commandes en mode "ligne", on peut écrire des programmes "shell" que l'on appelle communément "scripts"! Ce qui différencie les coquilles ci-dessus, c'est la programmation. Dans le cas de tcsh, la programmation sera près du langage C. Pour illustrer ces différences, voici un exemple de programme ("script") en tcsh:
#!
/bin/tcsh
echo
-n "Entrer votre nom: "
set nom=$<
if ($nom == "") then
echo "Vous n'avez pas
fourni votre nom."
else
echo "Votre nom est: $nom"
endif
Le programme équivalent en C est le suivant:
#include <stdio.h>
#include <string.h>
main()
{
char nom[25];
char *gets();
printf("Entrer votre nom:
");
*gets(nom);
if (strcmp(nom,"") == 0)
{
printf("Vous n'avez pas fourni
votre nom.\n");
}
else
{
printf("Votre nom est:
%s\n",nom);
}
}
Dans le cas d'un programme bash, on aura:
#!
/bin/bash
echo
-n "Entrer votre nom: "
read nom
if [ "$nom" = "" ]
then
echo "Vous n'avez pas fourni votre
nom."
else
echo "Votre nom est: $nom"
fi
Si on compare avec tcsh, on remarque que dans la condition if, on utilise [] au lieu () en tcsh. Aussi, pour terminer la condition if, on termine avec fi au lieu de endif en tcsh.
Lorsque vous entrez dans votre compte sous Linux, la coquille par défaut est bash. Une connaissance minimale de cette coquille est essentielle. Voici quelques caractéristiques de celle-ci:
Ø Obtenir l'historique des commandes exécutées
Ø
Rappeler des commandes à l'aide de !!, !# et !commande
Ø Modifier une commande déjà exécutée
Ø Rappeler des commandes à l'aide des flèches
Ø Compléter le nom d'une commande ou d'un fichier à l'aide du tabulateur
Ø Fixer une variable d'environnement
Ø etc.
Voyons quelques exemples concrets pour illustrer les caractéristiques ci-dessus.
Ø Obtenir l'historique des commandes exécutées
Il existe une fonction dans bash, aussi valide dans tcsh, pour connaître les commandes exécutées. C'est la fonction history qui est intégrée directement dans la coquille. Voici un exemple de celle-ci dans lequel on utilise des commandes Unix en bash et ensuite on fait afficher la liste des commandes :
[berube@gut prog]$ ls -l
total 2
drwxr-xr-x 4
berube hacker 1024 Apr 17 13:29 perl
drwxr-xr-x 2
berube hacker 1024 Apr 30 09:22 tcl
[berube@gut prog]$ pwd
/home/berube/prog
[berube@gut prog]$ date
Tue
Jul 31 07:36:38 EDT 2001
[berube@gut prog]$ history
...
639 ls -l
640 pwd
641 date
642 history
[berube@gut prog]$
Dans l'exemple ci-dessus, on fait afficher la liste des fichiers en utilisant la commande ls avec l'option -l. Par la suite, on utilise la commande pwd et enfin la commande date. On utilise ensuite la fonction history qui affiche les 500 dernières commandes exécutées. On voit donc que la 639ième commande exécutée était ls -l, la 640ième commande pwd, etc. Le numéro de commande (639, 640, ...) sera expliqué ci-dessus. Donc on peut voir quelles commandes vous avez exécutées et si quelqu'un utilise votre compte à votre insu, vous pourriez savoir quelles commandes cette personne a exécutées dans votre compte !
Ø
Rappeler des commandes à l'aide de !!, !# et !commande
Il est possible de rappeler des commandes sans avoir à les ressaisir. Si par exemple, l' on veut rappeler la dernière commande, on entre !! à l'invite ("prompt") de la coquille. Si, par contre, l'on veut rappeler une commande déjà exécutée, on peut le faire avec !# où # est le numéro de commande que l'on a vu ci-dessus. On peut même mettre un nombre négatif ! Aussi, on peut rappeler une commande déjà exécutée en tapant le début de la commande.
Voici des exemples plus complets:
[berube@gut
prog]$ tail /etc/rc.d/init.d/sendmail
status sendmail
RETVAL=$?
;;
*)
echo
"Usage: sendmail {start|stop|restart|condrestart|status}"
exit 1
esac
exit
$RETVAL
[berube@gut prog]$ ps -ef | grep sendmail
root
566 1 0 Apr26 ? 00:00:00 sendmail: accepting connections
berube 3977
25759 0 07:48 pts/7 00:00:00 grep sendmail
[berube@gut prog]$
[berube@gut prog]$ date
Tue
Jul 31 07:48:50 EDT 2001
[berube@gut prog]$ who
berube
:0 Jul 27 06:32
[berube@gut prog]$ history
650 tail /etc/rc.d/init.d/sendmail
651 ps -ef | grep sendmail
652 date
653 who
654 history
[berube@gut prog]$
On peut donc rappeler la commande 651 comme suit:
[berube@gut prog]$ !651
ps -ef | grep sendmail
root
566 1 0 Apr26 ? 00:00:00 sendmail: accepting connections
berube 3989
25759 0 07:51 pts/7 00:00:00 grep sendmail
[berube@gut prog]$
Ici on exécute la commande 651, soit exactement ce que l'on avait exécuté, et ce sans à avoir à resaisir la commande au complet !
On peut aussi la redemander comme suit:
[berube@gut prog]$ history
660 ps -ef | grep sendmail
661 history
[berube@gut prog]$ !-2
ps -ef | grep sendmail
root
566 1 0 Apr26 ? 00:00:00 sendmail: accepting connections
berube 3991
25759 0 07:51 pts/7 00:00:00 grep sendmail
[berube@gut prog]$
Ici, on utilise d'abord la commande history pour connaître le numéro de la commande et on soustrait 2 au numéro de la prochaine commande que l'on exécutera : ici !-2. En effet, quand on exécutera la prochaine commande, son numéro sera 662. Donc, si on soustrait 2 à 662, on arrive à 660 soit le numéro de commande qui correspond à la commande ps.
[berube@gut prog]$ !ps
ps -ef | grep sendmail
root
566 1 0 Apr26 ? 00:00:00 sendmail: accepting connections
berube 3993
25759 0 07:59 pts/7 00:00:00 grep sendmail
[berube@gut prog]$
Ici on demande que la dernière commande ps soit réexécutée ! Il n'est pas nécessaire d'entrer le nom de la commande au long. Si l'on veut rappeler la dernière commande history, on peut faire ceci:
[berube@gut prog]$ !hist
history
...
660 ps -ef | grep sendmail
661 history
662 ps -ef | grep sendmail
663 ps -ef | grep sendmail
664 history
[berube@gut prog]$
Lorsque l'on connaît ces trucs, on peut éviter de resaisir des commandes à répétition !
Ø Modifier une commande déjà exécutée
Il est possible de modifier une commande que l'on a déjà exécutée. Si, par exemple, l'on a saisi une commande et que l'on a fait une erreur de syntaxe, on peut la corriger en utilisant le caractère ^. Voici un exemple:
[berube@gut
projets]$ ps -ef | grep root | grep senhdmail
[berube@gut
projets]$ ^enh^en
ps -ef | grep root | grep sendmail
root
566 1 0 Apr26 ? 00:00:00 sendmail: accepting connections
[berube@gut projets]$
Dans l'exemple ci-dessus, on n'avait pas écrit correctement sendmail. On avait introduit un h dans le mot. Donc au lieu de resaisir la commande au complet, on a utilisé le ^. Le premier ^ indique que l'on veut rechercher la chaîne de caractères qui le suit, soit enh. Le second caractère ^ indique la valeur de remplacement de la chaîne associée au premier ^. La substitution avec le caractère ^ s'utilise seulement avec la dernière commande exécutée.
Pour modifier une commande que l'on a déjà exécutée, on utilisera le rappel d'une commande antérieure ( ! ! ou !# ou !commande) suivie, et ce sans espace, du caractère : et de paramètres. Voici le cas où l'on a déjà utilisé une commande mais dont on veut changer un caractère.
[berube@gut projets]$ history
...
732 ps -ef | grep root | grep senhdmail
733 ps -ef | grep root | grep sendmail
734 ps -ef | grep root | grep sdmail
735 history
[berube@gut projets]$
On veut donc réexécuter la commande 733 mais en changeant sendmail pour http. Voici ce qu'il faut faire pour y arriver:
[berube@gut
projets]$ !733:s/sendmail/http/
ps -ef | grep root | grep http
root
10575 1 0 Jul17 ? 00:00:00 /usr/local/apache/bin/httpd
[berube@gut projets]$
Donc, on indique que l'on veut rappeler la commande 733 suivie du caractère : et qui est suivi de s pour substitution, suivi /sendmail pour rechercher la chaîne de caractères sendmail, suivie de http/ pour la chaîne de caractères qui remplace sendmail. Si vous avez déjà utilisé l'éditeur vi, la syntaxe est similaire.
Ø Rappeler des commandes à l'aide des flèches
Avec Linux, il existe un autre truc plus simple d'utilisation pour rappeler une commande que l'on a déjà utilisée. Il suffit d'utiliser la flèche vers le haut pour reculer dans l'historique des commandes et la flèche vers le bas pour remonter dans celle-ci. La commande s'affiche et vous pouvez même modifier la commande avant de l'exécuter car les flèches ne font que réécrire le nom de la commande sans l'exécuter.
Ø Compléter le nom d'une commande ou d'un fichier à l'aide du tabulateur
Il est possible, avec l'utilisation de la touche de tabulation (tabulateur), de compléter le nom d'une commande ou le nom d'un fichier. Par exemple, on veut exécuter la commande suivante:
ls
/etc/services
Normalement, on doit saisir au long la commande et ses arguments. Pour éviter de resaisir la commande au complet, on saisira ceci :
ls
/etc/ser
Pour compléter le nom du fichier, on enfonce la touche Tab et automatiquement, s'il n'y a pas d'autres fichiers qui commencent par ser dans le répertoire /etc, le nom va apparaître au long !
Pour illustrer ceci, car c'est impossible dans ce document, on écrira :
sh-2.04$
ls /etc/ser[tab]vices
Cette notation permet d'illustrer d'autres exemples ci-dessous.
Si l'on veut compléter le nom d'une commande, on peut aussi le faire. On utilise le même procédé que précédemment.
Lorsque l'on utilise la touche de tabulation, le "shell" va chercher à compléter la commande ou le nom de fichier en regardant soit dans ses chemins d'accès de commande ou soit dans le répertoire courant ou celui spécifié dans la ligne de commande. Pour bien comprendre, reprenons l'exemple avec la commande ls ci-dessus. Le "shell" va rechercher dans le répertoire /etc un nom de fichier qui débute par ser. Comme c'est le seul fichier, il le complète automatiquement. Si l'on avait plutôt fait se au lieu de ser, rien n'aurait été complété. À ce moment, pour connaître la liste des fichiers commençant par se dans /etc, on aurait ceci:
sh-2.04$
ls /etc/se[tab][tab]
securetty
security sendmail.cf services
sh-2.04$
On peut donc utiliser ce truc plusieurs fois pour une même commande.
Pour terminer cette introduction à la coquille ("shell") bash, il faut aussi parler des variables d'environnement par défaut. Pour en connaître la liste, on utilise la commande interne de la coquille ("shell") env. Dans le cas de la coquille csh, on utilisera setenv.
Voici un exemple:
[berube@gut berube]$ env
PWD=/home/berube
HOSTNAME=gut.cti.ulaval.ca
QTDIR=/usr/lib/qt-2.2.0
LESSOPEN=|/usr/bin/lesspipe.sh %s
KDEDIR=/usr
USER=berube
LS_COLORS=no=00:fi=00:di=01;34:ln=01;36:pi=40;33:so=01;35:bd=40;33;01:cd=40;33;0
tm=01;32:*.bat=01;32:*.sh=01;32:*.csh=01;32:*.tar=01;31:*.tgz=01;31:*.arj=01;31:*.taz=01;31:*.lzh=01;31:*.zip=01;31:*.z=01;31:*.Z=01;31:*.gz=01;31:*.bz2=01;31:*.bz=01;31:*.tz=01;31:*.rpm=01;31:*.cpio=01;31:*.jpg=01;35:*.gif=01;35:*.bmp=01;35:*.xbm=01;35:*.xpm=01;35:*.png=01;35:*.tif=01;35:
MACHTYPE=i386-redhat-linux-gnu
LANG=en_US
COLORTERM=
DISPLAY=:0
LOGNAME=berube
SHLVL=3
SHELL=/bin/bash
HOSTTYPE=i386
OSTYPE=linux-gnu
HOME=/home/berube
TERM=xterm
SSH_ASKPASS=/usr/libexec/openssh/gnome-ssh-askpass
PATH=~/bin:/bin:/usr/bin:/usr/X11R6/bin:/opt/kde2/bin:/usr/lib/kde2/bin:/usr/local/bin
_=/usr/bin/env
OLDPWD=/home/berube/tmp/barcode-0.96
[berube@gut berube]$
Sans passer en revue toutes les variables ci-dessus, en voici quelques-unes. Les variables essentielles à connaître sont:
Ø
PWD
Elle contient le nom du répertoire courant. Donc si l'on change de répertoire, la variable sera mise à jour automatiquement.
Ø
HOSTNAME
Elle contient le nom de la machine Linux, soit celui qui a été défini lors de l'installation du système.
Ø
USER et LOGNAME
Elles contiennent le nom d'usager du compte dans lequel vous travaillez.
Ø
DISPLAY
Cette variable permet de définir vers quelle destination on veut afficher des fenêtres X11. Par défaut, on aura :0, soit à la console. Par contre, si l'on est branché à distance sur une machine Unix et que l'on veut faire afficher une fenêtre sur une machine locale, on fixera cette variable comme suit :
[berube@gut
tmp]$ DISPLAY=gut.cti.ulaval.ca :0
[berube@gut tmp]$ export DISPLAY
[berube@gut tmp]$
Donc, on fixe la variable DISPLAY et la commande export force la coquille à la rendre active immédiatement pour tous les autres scripts qui s'exécuteront et aux coquilles enfants.
Ø
SHELL
Elle contient le nom avec chemin d'accès de la coquille ("shell") courante. Dans le cas ci-dessus, on utilise /bin/bash.
Ø
HOME
Elle contient le nom du répertoire de travail par défaut lorsque vous entrez dans votre compte Linux.
Ø
TERM
Elle contient le type de terminal défini. Vous n'avez pas à fixer cette variable sauf si vous travaillez à distance et que vous utilisez telnet ou ssh. Il faut alors fixer la variable TERM pour "émuler" un terminal VT100. On le fait comme suit (cas d'une coquille bash):
[berube@gut tmp]$ TERM=vt100
[berube@gut tmp]$ export TERM
[berube@gut tmp]$
Donc on fixe la variable TERM et la commande export force la coquille à la rendre active immédiatement pour tous les autres scripts qui s'exécuteront et aux coquilles enfants.
Ø
PATH
Elle contient les chemins d'accès définis. Donc lorsque vous exécutez une commande, cette variable est consultée comme suit:
On vérifie si la commande existe dans le répertoire ~/bin. Ici le ~ est remplacé par le contenu de la variable HOME. Si la commande ne se trouve pas dans le répertoire ~/bin, la coquille va vérifier dans /bin, sinon, dans /usr/bin, ..., jusque dans /usr/local/bin. Si la commande ne peut être localisée, on aura le message d'erreur suivant:
command not found
Ceci arrive souvent si vous avez fait un script Perl, par exemple, dans le répertoire courant dans lequel vous vous retrouvez. Il faut alors spécifier avant la commande ./. Voici un exemple:
[berube@gut
travail1]$ info_fichier
bash: info_fichier: command not found
[berube@gut
travail1]$ ./info_fichier -k travail.no1.txt
Information
sur le fichier:
Nom
du fichier: travail.no1.txt
Taille:
2 Ko.
Proprietaire:
berube (249)
Groupe:
hacker (249)
Date
de derniere modification: 2001-07-23 a 07:48
[berube@gut
travail1]$
Donc on voit que si l'on ne spécifie pas ./info_fichier, on a le message d'erreur command not found. Si l'on veut éviter ce genre de problème, on peut modifier le fichier .bashrc en ajoutant à la fin de ce fichier, à moins que vous l'ayez déjà fait, ceci :
PATH=$PATH:.
export PATH
On peut évidemment modifier cette variable dans la coquille bash courante, mais il faut le faire à chaque fois qu'une nouvelle coquille est appelée.
Enfin, avec la coquille bash, on peut définir ses propres variables. Par
exemple, pour définir la variable tarte dont le contenu sera pommes, on fait
ceci :
[berube@gut berube]$ tarte="Pommes"
[berube@gut berube]$ export tarte
[berube@gut berube]$
Il est très important de ne pas laisser d'espace entre tarte, = et le double apostrophe ("). En effet, si par exemple, on fait ceci:
[berube@gut
berube]$ tarte = "Pommes"
La coquille va croire que l'on veut exécuter la commande tarte et l'on aura ceci:
bash: tarte: command not found
La commande export permet de spécifier à la coquille que l'on veut que la variable tarte soit visible dans tous les scripts bash qui seront exécutés dans la coquille courante. Pour illustrer ceci, voici un exemple simple. Supposons que l'on a le script bash suivant :
[berube@gut berube]$ cat /tmp/script.bash
#!
/bin/bash
echo
"La variable planche contient ceci: $planche."
[berube@gut berube]$
Donc on fixe la variable planche à burton, mais on ne fera pas la commande export juste après l'avoir définie. On va plutôt exécuter le script script.bash sans le faire. On aura ceci :
[berube@gut
berube]$ planche="Burton"
[berube@gut
berube]$ /tmp/script.bash
La
variable planche contient ceci: .
[berube@gut berube]$
Maintenant, faisons un export de la variable et réexécutons
le script. On aura alors ceci:
[berube@gut
berube]$ export planche
[berube@gut
berube]$ /tmp/script.bash
La
variable planche contient ceci: Burton.
[berube@gut berube]$
On voit donc que le script bash a hérité du contenu de la variable planche.
Ceci complète donc un petit survol de la coquille bash.
6.Système de fichiers
Le système de fichiers sur Linux est similaire à ce que l'on retrouve dans Windows, i.e. une structure hiérarchique dont une racine et des répertoires qui s'y rattachent. Voici un exemple d'un système Linux:
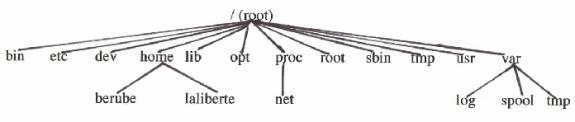
Comme illustré ci-dessus, il existe plusieurs répertoires qui sont rattachés à la racine (/). Voici un résumé de ce que contiennent ces répertoires.
Ø
/bin
Ce répertoire contient les commandes de base du système, comme les coquilles ("shells") et les commandes de base d'Unix, i.e. cat, date, grep, mv, ....
Ø
/etc
Ce répertoire contient l'ensemble des fichiers de configuration et de démarrage d'un système Linux. On y retrouve entre autres, le fichier contenant la liste des usagers Unix (/etc/passwd), les "scripts" de démarrage du système, les fichiers de configuration pour certains logiciels, etc.
Ø
/dev
Ce répertoire contient les dispositifs ("devices") du système. On y retrouve des dispositifs de type bloc (disque) et ceux de type caractère (unité de ruban, port série, ...). Par exemple, un disque SCSI aura un nom de dispositif qui débutera par sd ("SCSI device"), et un disque de type IDE par hd ("Hard disk"), une unité de disquette par fd ("floppy disk"), etc. Donc, pour chaque dispositif, il y aura une correspondance dans ce répertoire.
Ø
/home
Ce répertoire contient généralement l'espace disque nécessaire pour les comptes d'usager. Comme illustré ci-dessus, on a 2 usagers Linux, soient berube et laliberte. Par défaut, c'est dans le répertoire /home que l'utilitaire useradd ajoutera le répertoire d'un usager.
Ø
/lib
Ce répertoire contient les librairies de système pour le fonctionnement d'un système Linux. Si l'on veut comparer à Windows, elles sont comme les DLL.
Ø /opt
Ce répertoire est utilisé par certains logiciels qui ne font pas partie du système d'exploitation. Son contenu va dépendre de la distribution de Linux que l'on utilise. Dans le cas de SuSE, soit la distribution qui est utilisée au département d'informatique, elle ne contient rien.
Ø
/proc
Ce répertoire contient tous les renseignements qui se rattachent aux processus actifs d'un système Linux. On y retrouve des répertoires qui contiennent des renseignements sur les processus qui s'exécutent ainsi que ceux concernant le type de processeur, les dispositifs actifs ("devices"), l'utilisation de la mémoire, etc. Par exemple, si on veut savoir quel type de processeur une machine Linux possède, il suffit de regarder le contenu du fichier cpuinfo.
[berube@gut adm]$ cat /proc/cpuinfo
processor
: 0
vendor_id
: GenuineIntel
cpu family : 6
model
: 5
model name
: Pentium II (Deschutes)
stepping
: 2
cpu MHz
: 399.087
cache size
: 512 KB
fdiv_bug
: no
hlt_bug
: no
sep_bug
: no
f00f_bug
: no
coma_bug
: no
fpu : yes
fpu_exception
: yes
cpuid level
: 2
wp
: yes
flags
: fpu vme de pse tsc msr pae mce cx8 sep mtrr pge mca cmov pat pse36 mmx
fxsr
bogomips
: 796.26
[berube@gut adm]$
Ø
/root
Ce répertoire correspond au répertoire de travail de l'usager root.
Ø
/sbin
Ce répertoire contient l'ensemble des commandes pour l'administration d'un système Linux. On y retrouve des commandes pour redémarrer le système (reboot), vérifier l'intégrité d'une partition (fsck), créer un système de fichier (mkfs) , etc.
Ø
/tmp
Ce répertoire est utilisé par l'ensemble du système autant pour l'usager root que pour les usagers Linux. Plusieurs applications l'utilisent pour y mettre des fichiers et répertoires temporaires. N'importe quel usager du système peut y mettre des fichiers. Cependant, lorsque le système est redémarré, certains fichiers seront effacés.
Ø
/usr
Ce répertoire contient un ensemble de sous-répertoires dont certains contiennent des commandes Linux (bin/), des fichiers .h pour ceux et celles qui veulent écrire des programmes C (include/), d'autres librairies de système (lib/), ainsi que des pages de manuels (man/) et bien d'autres fichiers.
Ø
/var
Ce répertoire contient des journaux ("logs") de système (log/), des boîtes de courrier (spool/mail/), de l'espace temporaire pour l'envoi de courrier (spool/mqueue/), etc. Aussi, il existe un sous-répertoire temporaire (tmp/) qui a les mêmes caractéristiques que /tmp.
Le système de fichiers Linux devient donc important pour quelqu'un qui administre un système Linux ou bien fait du développement.
Ce qui caractérise un système de fichiers Unix, c'est que tout est vu comme un fichier. On peut les catégoriser comme suit:
· Fichiers réguliers
· Répertoires
· Dispositifs ("devices")
·
Sockets
·
Named
pipes
·
Liens
stricts ("hard links")
· Liens symboliques ("symbolic links")
Sans entrer dans les détails pour chaque type de fichier, on appelle un fichier régulier celui qui contient du texte ou des données binaires, i.e. un exécutable, un fichier de base de données, etc. Les dispositifs sont donc des fichiers qui sont associés aux composants matériels, i.e. un disque rigide, une unité de disquettes, etc. Les sockets sont des fichiers spéciaux qui permettent de communiquer par réseau. Ce sont les sockets qui interviennent lorsque vous utilisez un navigateur pour vous brancher à un serveur Web. Les "named pipes" sont des fichiers spéciaux qui permettent la communication interprocessus à l'intérieur d'un système Linux. Enfin, il existe la notion de liens strict et symbolique. Un lien strict permet de faire pointer un nom de fichier directement aux données contenues dans un fichier tandis qu'un lien symbolique pointe vers un nom de fichier et non vers son contenu. Si l'on détruit le fichier original, le lien symbolique sera brisé tandis qu'un lien strict ne le sera pas et il pointera sur les données que contenaient le fichier original. On utilise plus souvent le lien symbolique que le lien strict.
Pour déterminer à quel type de fichier on a affaire, on utilise la commande ls avec l'option -l. Voyons un exemple de la commande ls -l :
[berube@gut
exemples]$ ls -l
total 4
-rwxr-xr-x 1
berube hacker 56 Aug 7 07:07 executable
-rw-r--r-- 2
berube hacker 40 Aug 7 07:06 fichier
-rw-r--r-- 2
berube hacker 40 Aug 7 07:06 fichier_lien_strict
-rw-r--r-- 1
berube hacker 0 Aug 7 07:05 fichier_vide
lrwxrwxrwx 1 berube
hacker 12 Aug 7 07:06 lien_symbolique_fichier_vide ->
fichier_vide
lrwxrwxrwx 1
berube hacker 10 Aug 7 07:05 lien_symbolique_repertoire -> repertoire
drwxr-xr-x 2 berube
hacker 1024 Aug 7 07:04 repertoire
[berube@gut
exemples]$
Avec cette commande, on obtient une foule de renseignements pertinents. Si l'on prend la première ligne qui suit celle total 4, on a d'abord les permissions sur le fichier (-rwxr-xr-x), le nombre de liens stricts (1), le propriétaire du fichier (berube), le groupe auquel appartient le fichier (hacker), la dimension du fichier en octets (56), la date de modification du fichier (Aug 7 07:07), ainsi que le nom du fichier. Donc si on revient sur les permissions, la première position, ici -, correspond au type de fichier. Dans ce cas-ci, un - correspond à un fichier régulier. Voici un tableau des types:
|
Type |
Description |
|
- |
Fichier régulier |
|
d |
Répertoire |
|
c |
Dispositif de type caractères |
|
b |
Dispositif de type bloc |
|
s |
Socket |
|
p |
Named
pipe |
|
l |
Lien symbolique |
Donc on peut voir que le fichier repertoire est un répertoire (drwxr-xr-x), que les fichiers lien_symbolique_fichier_vide et lien_symbolique_repertoire sont des liens symboliques vers fichier_vide et repertoire. On peut donc avoir un lien symbolique pointant soit vers un fichier ou soit vers un répertoire. On remarque le fichier fichier_lien_strict est un lien strict et dont le nombre de liens est égal à 2. Donc, si l'on détruit le fichier fichier, le fichier fichier_lien_strict contiendra le contenu du fichier fichier.
Si nous revenons aux permissions, elles sont représentées sur 15 bits dont les 3 premiers bits correspondent au type de fichier. Les 12 autres permettent de fixer les permissions pour l'usager, le groupe et les autres. En effet, sur Unix un fichier est toujours rattaché à un propriétaire que l'on appelle usager. Il est possible de fixer la permission de lecture (r) sur le fichier, la permission d'écriture (w) et la permission d'exécution (x). On peut faire
de même pour les permissions de groupe, car un usager est toujours associé à un groupe. Ce groupe permet à un ensemble d'usagers ayant un projet commun de partager des ressources communes. Cette notion est la même que celle que l'on retrouve dans le monde Windows. Enfin, pour les gens (autres usagers) qui ne font pas partie d'un même groupe, il existe des permissions pour leur donner accès.
Donc si on revient avec l'exemple de la commande ls ci-dessus, on peut voir que pour le fichier ayant pour nom executable, les permissions pour le propriétaire sont lecture, écriture et exécution, i.e. rwx. Pour le groupe, les permissions sont lecture et exécution, i.e. r-x. Enfin pour les autres, les permissions sont lecture et exécution, tout comme pour les permissions de groupe. Aussi, on retrouvera certaines permissions spéciales qui sont représentées sur 3 bits et elles s'appliquent sur le bit d'exécution. On a
le "setuid bit", le "setgid bit" et le "sticky bit". Le "setuid bit" permet que lors de l'exécution de ce fichier, cette commande sera exécutée non pas sous votre identité mais celle à qui appartient le programme. Ce genre de commande permet de donner des privilèges temporaires à un usager. Au lieu d'avoir pour le propriétaire les permissions suivante : rwx, on aura plutôt rws. Donc le s, s'il est situé sur les permissions du propriétaire, indique que l'on a un "setuid bit". Si ce s se retrouve sur les permissions du groupe, on parle alors de "setgid bit", i.e. la commande sera exécutée sous votre identité mais avec le groupe auquel appartient cette commande. Par exemple, vous voulez écrire un programme qui doit écrire dans un répertoire mais vous ne voulez pas être obligé(e) de déclarer tous les usagers du système dans ce groupe et vous ne voulez pas permettre à tous d'écrire dans ce répertoire. On utilise alors le "setgid bit" et l'on fera en sorte que le répertoire ait des permissions d'écriture pour le groupe. Enfin, il y a le
"sticky bit" qui lui s'applique sur les permissions pour les autres usagers. Il s'utilise pour des répertoires comme /tmp et /var/tmp. Ce bit permet d'éviter qu'un usager du système n'efface vos fichiers temporaires même s'il y a un accès en lecture et écriture sur ces répertoires. Donc, les permissions pour les autres usagers seront rwt, donc un t à la place d'un x.
7.Commandes Unix
Une des forces d'Unix, c'est son ensemble de commandes que certains qualifieront de "cryptique". Il faut en connaître un minimum pour être en mesure de bien maîtriser un environnement Unix et faire du développement. Parfois, il est beaucoup plus efficace d'utiliser les commandes que de se servir des utilitaires graphiques. Avec la notion de "pipe", on verra que l'on peut faire des choses puissantes sur une seule ligne de commandes. On commence à voir sur Windows quelques commandes à la saveur Unix.
Donc, on a vu ci-dessus des commandes comme ls, ps et grep. Ce sont des commandes essentielles dans le cadre du cours Implantation d'un site Internet, car elles vont vous permettre de réaliser les différents exercices et travaux pratiques. Pour chaque commande Unix, il existe une série d'options pour celle-ci. Généralement, la ou les options sont précédées d'un tiret (-). On verra des exemples concrets pour bien comprendre le fonctionnement de celles-ci.
Voici une liste des différentes commandes qu'il serait souhaitable de maîtriser.
|
Commande |
Utilisation |
Options |
|
awk |
Extraire des champs dans un fichier |
-F |
|
cat |
Voir le contenu d'un fichier |
|
|
cd |
Changer de répertoire |
|
|
chmod |
Changer les permissions sur un fichier |
|
|
cp |
Copier le contenu d'un fichier |
ir |
|
date |
Obtenir la date du système |
|
|
df |
Voir la table des partitions avec l'espace disque utilisé |
k |
|
diff |
Comparer deux fichiers |
c |
|
du |
Obtenir l'espace disque occupé dans un répertoire |
-ks |
|
echo |
Faire afficher le contenu d'une variable d'une coquille |
|
|
grep |
Extraire une ou des lignes d'un fichier dont un des arguments est une chaîne de caractères |
-iv |
|
find |
Permettre de faire une recherche dans le système de fichier et de prendre action sur cette recherche |
|
|
kill |
Tuer un processus |
|
|
ln |
Créer un lien strict ou un lien symbolique |
-s |
|
ls |
Voir la liste des fichiers |
-alt |
|
man |
Consulter la page de manuel d'une commande Unix |
|
|
mkdir |
Créer un répertoire |
-p |
|
more |
Voir le contenu d'un fichier mais dont l'affichage se fait par page |
|
|
mv |
Renommer un fichier ou un répertoire |
-i |
|
od |
Voir le contenu d'un fichier en format octal |
-c |
|
passwd |
Changer de mot de passe |
|
|
pico |
Éditer un fichier |
|
|
ps |
Voir la liste des processus qui s'exécutent dans le système |
-aux-ef |
|
pwd |
Connaître le nom du répertoire courant |
|
|
rm |
Effacer un fichier |
-rfi |
|
rmdir |
Effacer un répertoire |
-p |
|
sed |
Rechercher une chaîne de caractères dans un fichier et la remplacer |
-f |
|
tail |
Afficher les 10 dernières lignes d'un fichier |
-f |
|
tar |
Créer un fichier d'archivage |
-cxtvf |
|
umask |
Fixer les permissions par défaut lors de la création de fichiers |
|
|
vi |
Éditer un fichier |
|
En plus des commandes ci-dessus, il y a la notion de pipe (|) qui est très importante en Unix. En effet, le pipe permet de rediriger la sortie ("output") d'une commande comme entrée ("input") d'une autre commande. Pour l'illustrer, prenons l'exemple de l'utilisation de la commande ls et pour laquelle la sortie ("output") s'affichera sur plusieurs pages-écrans. Donc, si l'on utilise la commande ls et qu'il y a plusieurs fichiers dans un répertoire, la commande va afficher tous les fichiers d'un trait. Pour pouvoir visualiser la liste, on utilise la commande more avec un pipe (|). Donc voici comment on l'utilise :
[berube@gut projets]$ ls | more
CORBA
DIR_COLORS
Muttrc
X11
adjtime
aliases
aliases.db
anacrontab
at.deny
autorpm.d
bashrc
cdrecord.conf
conf.linuxconf
cron.d
cron.daily
cron.hourly
cron.monthly
cron.weekly
crontab
csh.cshrc
--More--
Donc, la sortie ("output") de la commande ls sera redirigée comme l'entrée ("input") de la commande more. On peut donc utiliser autant de pipes (|) que l'on veut.
Sans entrer dans les détails, voyons quelques exemples concrets de l'utilisation des commandes ci-dessus.
Ø
awk
L'exemple ci-dessous permet d'extraire la liste des usagers du fichier /etc/passwd. Ce fichier sert pour conserver les renseignements nécessaires pour un compte Unix. Il a la structure suivante:
usager:x:UID:GID:Champ
commentaire:Repertoire_de_travail:coquille
Donc comme on le voit, chaque information est séparée par un :. Donc si l'on veut extraire la liste des usagers, on utilisera la commande awk comme suit:
{genesis:14}
awk -F: '{print $1}' /etc/passwd | more
root
daemon
bin
sys
adm
lp
smtp
uucp
nuucp
listen
nobody
noaccess
nobody4
berube
montigny
gagne
news
andre
ftp
gopherd
--More--
L'option -F permet de spécifier le délimiteur de champ, soit :. $1 correspond au champ 1. Si l'on avait voulu extraire le champ correspondant au répertoire, on aurait mis $6. Si l'on veut afficher le nom de l'usager et son répertoire de travail, on fera:
{genesis:15}
awk -F: '{print "Usager="$1" Repertoire="$6}' /etc/passwd |
more
Usager=root
Repertoire=/
Usager=daemon
Repertoire=/
Usager=bin Repertoire=/usr/bin
Usager=sys
Repertoire=/
Usager=adm
Repertoire=/var/adm
Usager=lp
Repertoire=/usr/spool/lp
Usager=smtp
Repertoire=/
Usager=uucp
Repertoire=/usr/lib/uucp
Usager=nuucp
Repertoire=/var/spool/uucppublic
Usager=listen
Repertoire=/usr/net/nls
Usager=nobody
Repertoire=/
Usager=noaccess
Repertoire=/
Usager=nobody4
Repertoire=/
Usager=berube
Repertoire=/home/berube
Usager=montigny
Repertoire=/home/montigny
Usager=gagne
Repertoire=/home/gagne
Usager=news
Repertoire=/usr/local/inn
Usager=andre
Repertoire=/home/andre
Usager=ftp
Repertoire=/home/anon-ftp
Usager=gopherd
Repertoire=/logiciels/gopherd
--More--
Dans l'exemple ci-dessus on voit qu'il est possible d'inclure des chaînes de caractères. Si l'on ne spécifie pas l'option -F par défaut, la commande considère que le séparateur de champs est un blanc. Aussi, si on veut utiliser comme séparateur de champs un tabulateur, on utilisera -F\t.
Pour en connaître plus sur l'utilisation de la commande awk, vous pouvez consulter les URLs suivants:
Documentation française format PDF
http://www.ai.univ-paris8.fr/~hw/unx5.pdf
Documentation en anglais
http://www.gnu.org/manual/gawk/html_chapter/gawk_3.html
Ø
cd
La commande cd ("change directory") permet de naviguer dans les répertoires. Donc si l'on veut se positionner dans le répertoire /etc, on fera ceci:
[berube@gut
berube]$ cd /etc
[berube@gut /etc]$
On peut spécifier .. pour signifier le répertoire juste au-dessus du répertoire courant que l'on représente par un point ("."). Si l'on veut à partir du répertoire /etc aller dans le répertoire /tmp, on peut le faire comme suit:
[berube@gut
/etc]$ cd ../tmp
[berube@gut /tmp]$
Ø
chmod
La commande chmod permet de changer les permissions sur un fichier. Il y a différentes manières de l'utiliser. On peu utiliser la notation octale ou bien une notation plus intuitive. On a vu ci-dessus que l'on a des permissions pour le propriétaire du fichier, le groupe auquel appartient le fichier ainsi que les autres usagers. Pour chaque catégorie de permissions (propriétaire, groupe et autres), on représente celles-ci sur 3 bits. Voici un tableau qui vous aidera à mieux comprendre la notation en octals que l'on verra plus bas.
|
Permission |
Octal |
Binaire |
|
rwx |
7 |
111 |
|
rw- |
6 |
110 |
|
r-x |
5 |
101 |
|
r-- |
4 |
100 |
|
-wx |
3 |
11 |
|
-w- |
2 |
10 |
|
--x |
1 |
1 |
|
--- |
0 |
0 |
Donc si l'on veut que le fichier ait les permissions suivantes:
· rwx pour le propriétaire (lecture, écriture et exécution)
· r-x pour le groupe auquel appartient le fichier (lecture et exécution)
· r-x pour les autres (lecture et exécution)
On utilisera la commande chmod comme suit:
chmod
755 fichier
Si par contre, on veut les permissions suivantes:
· rw- pour le propriétaire (lecture, écriture et exécution)
· r-- pour le groupe auquel appartient le fichier (lecture et exécution)
· r-- pour les autres (lecture et exécution)
On utilisera la commande chmod comme suit :
chmod
644 fichier
La notation octale peut être difficile à utiliser et c'est pourquoi, on peut utiliser la commande comme suit :
chmod
[ugoa]{+|=|-}[rwxst] fichier
Ce qui est entre [] indique que les paramètres sont facultatifs. Voici ce que signifie les lettres u, g, o et a.
· u : appliquer les permissions sur le propriétaire du fichier
· g : appliquer les permissions sur le groupe auquel le fichier appartient
· o : appliquer les permissions sur les autres
· a : appliquer les permissions sur le propriétaire, le groupe et les autres
Pour les lettres r, w, x, s et t, voici ce qu'elles signifient:
· r : appliquer (+) ou enlever (-) la permission de lecture
· w : appliquer (+) ou enlever (-) la permission d'écriture
· x : appliquer (+) ou enlever (-) la permission d'exécution
· s : appliquer (+) ou enlever (-) la permission de "setuid" ou de "setgid"
· t : appliquer (+) ou enlever (-) la permission de "sticky bit"
Donc on utilise le symbole + entre les permissions de l'appartenance au fichier et les permissions d'exécution, si celles-ci n'étaient pas actives, on les active. Si l'on veut les désactiver, on utilise le symbole -. Le symbole = indique que l'on veut exactement les permissions spécifiées. Donc, si une permission était active, mais que vous ne désirez plus qu'elle le soit, vous pouvez soit utiliser - ou bien utiliser =, ça revient au même.
Si l'on reprend les exemples ci-dessus, on aura:
chmod
755 fichier
deviendra
chmod
u=rwx fichier
chmod go=rx fichier
On peut aussi le faire mais en une seule commande:
chmod
u=rwx,go=rx fichier
Donc au lieu d'exécuter la commande chmod deux fois, on utilise la virgule pour séparer les permissions du propriétaire de celles de groupe et autres. On remarque que l'on peut mettre g et o ensemble, au lieu d'avoir écrit:
chmod
u=rwx,g=rx,o=rx fichier
Aussi, pour terminer cet exemple, on aurait pu écrire la ligne suivante:
chmod
u=rwx,go=rx fichier
Comme suit:
chmod ugo=rx,u+w fichier
Donc on force que le propriétaire, le groupe et les autres aient la permission de lecture et d'exécution et ensuite on active la permission d'écriture pour le propriétaire. Si l'on n'avait pas mis u+w, la permission aurait été:
r-xr-xr-x
Pour le cas suivant:
chmod
644 fichier
deviendra
chmod
u=rw,go=r fichier
ou
chmod
ugo=r,u+w fichier
Donc comme vous pouvez le constater, on peut fixer les permissions sur un fichier de différentes manières.
Ø
cp
La commande cp permet de copier le contenu d'un fichier dans un autre. On l'utilise donc comme suit:
cp
fichier_source fichier_destination
Donc on doit spécifier le fichier source (fichier_source) qui sera copié dans le nom de fichier destination (fichier_destination). Si le fichier destination existe, il sera alors écrasé par le contenu du fichier source. Pour éviter ce genre de problème, on peut spécifier l'option -i qui va vous demander de confirmer que vous voulez bien écraser le contenu du fichier destination. Voici un exemple:
[berube@gut berube]$ cp -i tarte tata
cp: overwrite `tata'?
Donc si l'on veut le faire, on spécifie y pour yes, sinon on spécifie n pour no.
Enfin, si l'on veut copier un répertoire ou bien l'ensemble des fichiers d'un répertoire ainsi que tous les sous-répertoires qui s'y rattachent, on utilisera l'option -r. On utilisera la commande suivante:
[berube@gut berube]$ cp -r /tmp .
[berube@gut berube]$
Donc, on copie le contenu de /tmp dans le répertoire courant que l'on représente par un point ("."). Il faut cependant s'assurer d'être dans le bon répertoire où l'on veut copier le contenu !
Ø
df
La commande df permet de connaître l'utilisation et la liste des partitions montées d'un système Unix. Il existe quelques options à la commande df, mais on utilisera généralement l'option -k qui permet d'afficher l'espace disque en kilooctets. Voici un exemple de l'utilisation de la commande df.
[berube@gut berube]$ df -k
Filesystem
1k-blocks Used Available
Use% Mounted on
/dev/sda8 256667
116227 127188 48% /
/dev/sda1 23302
5883 16216 27% /boot
/dev/sda5
4071744 2065408 1799504
54% /usr
/dev/sda7 256667 205766
37649 85% /var
/dev/sda6
3997830 1807288 1983707
48% /home
[berube@gut berube]$
On a donc 5 partitions, soient /, /boot, /usr, /var et /home. Leurs dimensions respectives sont 256667 kilooctets, 23302 kilooctets, 4071744 kilooctets, 256667 kilooctets et 3997830 kilooctets. La colonne Used indique l'espace disque qui est présentement utilisé, et la colonne Available indique l'espace disque libre. La colonne Use% est le pourcentage d'utilisation. Si l'on addition l'espace utilisé et l'espace libre, le résultat sera inférieur à l'espace total. En fait, un système Unix conserve toujours entre 5% et 10% d'espace pour optimiser la performance pour l'accès à la partition. Si l'on veut changer cette valeur, on utilise la commande tunefs. Enfin, la première colonne indique sur quel dispositif ("device") est associé à la partition. Donc / est associé au dispositif /dev/sd8, /boot au dispositif /dev/sda1, etc.
Ø
diff
La commande diff permet de comparer le contenu de deux fichiers. C'est particulièrement utile lorsque l'on modifie un programme dont on garde des copies des différentes versions. Par exemple, lorsqu'on utilise des logiciels du domaine public, il arrive parfois que l'on doive modifier certains fichiers. On conserve alors une copie du fichier original et on modifie le fichier. Voici un exemple d'un code source qui n'est pas supporté sur Linux.
root@mercure:/usr/local/nameserv/src/qi-3.1B7/lib
> diff -c util.c util.c.orig
***
util.c Mon Aug 6 13:56:36 2001
---
util.c.orig Mon Aug 6 11:59:04 2001
***************
*** 38,69 ****
static
char RcsId[] = "@(#)$Id: util.c,v
1.15 1994/09/09 20:15:13 p-pomes Exp $";
#endif
! #include <stdio.h>
!
! #define INT32 long
! #define NIL -1
! #define WORDSIZE
64
! #define NOLOG_OP
4
! #ifndef OPTIONS_H
! #define OPTIONS_H
! struct option
! {
!
char *opName;
!
char *opValue;
! };
! typedef struct option OPTION;
!
!
! #define ECHO_OP
0
! #define LIMIT_OP
1
! #define VERBOSE_OP
2
! #define ADDONLY_OP 3
! #define NOLOG_OP
4
!
! #define OP_VALUE(x) OptionList[x].opValue
!
#endif
#ifdef
__STDC__
#include
<stdarg.h>
--- 38,44 ----
static
char RcsId[] = "@(#)$Id: util.c,v
1.15 1994/09/09 20:15:13 p-pomes Exp $";
#endif
! #include "protos.h"
#ifdef
__STDC__
#include
<stdarg.h>
root@mercure:/usr/local/nameserv/src/qi-3.1B7/lib >
Dans l'exemple ci-dessus, on compare le fichier util.c (fichier modifié) avec le fichier util.c.orig (fichier original).
Voici comment interpréter le résultat de la commande :
Dans le fichier util.c, les lignes de 38 à 69 comportent des différences avec les lignes 38 à 44 du fichier util.c.orig. Lorsqu'une ligne commence par !, ceci indique les différences. Donc on peut voir que la ligne :
#include "protos.h"
du fichier util.c.orig a été remplacée par:
#include <stdio.h>
#define INT32 long
#define NIL -1
#define WORDSIZE
64
#define NOLOG_OP
4
#ifndef OPTIONS_H
#define OPTIONS_H
struct option
{
char *opName;
char *opValue;
};
typedef struct option OPTION;
#define ECHO_OP
0
#define LIMIT_OP
1
#define VERBOSE_OP
2
#define ADDONLY_OP 3
#define NOLOG_OP
4
#define
OP_VALUE(x) OptionList[x].opValue
#endif
On peut aussi avoir des lignes qui débutent par un + ou bien un -. Ceci indique que c'est une ligne ajoutée ou retranchée. Vous remarquerez que lorsqu'on indique les lignes qui diffèrent, les numéros de lignes sont précédés de *** pour faire référence au fichier util.c et --- pour faire référence au fichier util.c.orig.
Donc, la commande diff est très intéressante à connaître lorsque l'on fait du développement.
Ø
du
Cette commande du est très utile pour connaître l'espace disque dans un répertoire. Il existe deux options, soit -k pour que l'espace soit indiqué en kilooctets, et -s pour afficher l'espace total sans afficher l'espace disque utilisé dans chaque sous-répertoire. Voici un exemple pour illustrer ces deux options :
[berube@gut
barcode-0.96]$ du -k
29
./bookland
31
./compat
11
./debian
483 ./doc
4
./contrib
1394 .
[berube@gut
barcode-0.96]$
Donc on voit que le répertoire courant contient cinq sous-répertoires, soient bookland (29 ko), compat (31 ko), debian (11 ko), doc (483 ko) et contrib (4 ko). Le répertoire contient au total 1394 ko et il est représenté par ..
Si l'on veut avoir l'espace total sans avoir la liste des sous-répertoires, on utilise l'option
-s comme suit:
[berube@gut
barcode-0.96]$ du -ks
1394 .
[berube@gut barcode-0.96]$
Ø
echo
La commande echo permet d'afficher le contenu d'une variable d'environnement et les variables que l'on a définies dans la coquille ("shell"). Par exemple, si l'on veut savoir les chemins d'accès définis, on fera:
[berube@gut barcode-0.96]$ echo $PATH
~/bin:/bin:/usr/bin:/usr/X11R6/bin:/opt/kde2/bin:/usr/lib/kde2/bin:/usr/local/bin
[berube@gut barcode-0.96]$
Ø
grep
La commande grep est une des plus utiles d'Unix. Elle permet de rechercher une chaîne de caractères dans un fichier ASCII. Par exemple, si l'on veut trouver dans le fichier /etc/passwd, toutes les lignes qui contiennent la chaînes de caractères bash, on fera ceci:
[berube@gut berube]$ grep bash /etc/passwd
root:x:0:0:root:/root:/bin/bash
gdm:x:42:42::/home/gdm:/bin/bash
berube:x:249:49::/home/berube:/bin/bash
mysql:x:250:250:MySQL server:/var/lib/mysql:/bin/bash
capr:x:500:500:Carl Provencher:/home/capr:/bin/bash
[berube@gut berube]$
Il existe deux options intéressantes avec la commande grep, soient -i et -v. L'option -i permet de faire une recherche sans tenir compte de la casse. En effet, Unix fait une différence entre les majuscules et les minuscules et ce, pour les commandes et les variables. Pour illustrer cette option, voyons le cas suivant. Dans l'exemple ci-dessus, on voit que l'on a Carl dans la dernière ligne. Donc, si l'on avait utilisé la commande comme suit :
[berube@gut
berube]$ grep carl /etc/passwd
[berube@gut berube]$
On voit que la commande grep ne trouve aucune ligne contenant le mot carl. Par contre, si on utilise l'option -i, on aura :
[berube@gut berube]$ grep -i carl /etc/passwd
cpr:x:500:500:Carl Provencher:/home/cpr:/bin/bash
[berube@gut berube]$
Donc l'exemple ci-dessus illustre bien que la casse à de l'importance.
Une autre option bien utile avec grep, c'est -v. Ceci indique que l'on veut extraire les lignes dont les lignes ne contiennent pas la chaîne de caractères recherchés. Supposons que dans le premier exemple ci-dessus, on ne veuille pas conserver les lignes qui contiennent /home/. On utilisera la commande comme suit :
[berube@gut berube]$ grep bash /etc/passwd | grep -v
/home/
root:x:0:0:root:/root:/bin/bash
mysql:x:250:250:MySQL
server:/var/lib/mysql:/bin/bash
[berube@gut berube]$
On voit donc que les lignes gdm, berube et capr n'apparaissent plus. On peut aussi utiliser les options -iv ensemble. Si dans le premier exemple, on veut obtenir toutes les lignes contenant bash mais que l'on ne veut pas celles contenant le mot carl, on fera ceci:
[berube@gut berube]$ grep bash /etc/passwd | grep -iv
carl
root:x:0:0:root:/root:/bin/bash
gdm:x:42:42::/home/gdm:/bin/bash
berube:x:249:49::/home/berube:/bin/bash
mysql:x:250:250:MySQL
server:/var/lib/mysql:/bin/bash
[berube@gut berube]$
Enfin, on peut aussi utiliser des expressions régulières avec la commande grep. Si l'on veut, par exemple, trouver toutes les lignes du fichier /etc/passwd qui débutent par la lettre b, on fera ceci:
[berube@gut berube]$ grep -i "^b"
/etc/passwd
bin:x:1:1:bin:/bin:
berube:x:249:49::/home/berube:/bin/bash
[berube@gut berube]$
Donc le symbole ^ permet de spécifier un début de ligne, à ne pas confondre avec le caractère ^ dont on a parlé précédemment. On peut aussi mettre la chaîne de caractères entre doubles apostrophes (") comme dans l'exemple ci-dessus. Dans cet exemple, ils ne sont pas obligatoires. Elles le deviennent lorsque l'on veut insérer un blanc dans la chaîne à rechercher.
On voit donc que grep est une commande très utile sur Unix.
Ø
find
La commande find permet de faire des recherches dans le système de fichiers. Par exemple, on veut rechercher tous les fichiers dont le nom contient passwd dans celui-ci et qui seraient situés dans le répertoire /etc. On utilisera la commande comme suit:
[berube@gut
berube]$ find /etc -name '*passwd*' -print
/etc/X11/applnk/System/userpasswd.desktop
/etc/passwd
/etc/rc.d/init.d/yppasswdd
/etc/rc.d/rc0.d/K34yppasswdd
/etc/rc.d/rc1.d/K34yppasswdd
/etc/rc.d/rc2.d/K34yppasswdd
/etc/rc.d/rc3.d/K34yppasswdd
/etc/rc.d/rc4.d/K34yppasswdd
/etc/rc.d/rc5.d/K34yppasswdd
/etc/rc.d/rc6.d/K34yppasswdd
find:
/etc/default: Permission denied
/etc/passwd-
find: /etc/httpd/conf/ssl.crl: Permission denied
find: /etc/httpd/conf/ssl.crt: Permission denied
find: /etc/httpd/conf/ssl.csr: Permission denied
find: /etc/httpd/conf/ssl.key: Permission denied
find: /etc/httpd/conf/ssl.prm: Permission denied
/etc/pam.d/passwd
find:
/etc/autorpm.d: Permission denied
/etc/vmware/vmnet1/smb/private/smbpasswd
[berube@gut berube]$
L'utilisation de cette commande est donc la suivante:
/etc est le nom du répertoire où l'on veut faire la recherche. Si l'on avait mis un point (".") au lieu du nom de répertoire, la recherche aurait été effectuée dans le répertoire courant. On peut aussi utiliser le double point ("..") pour représenter le répertoire juste au-dessus du répertoire courant. Ensuite, on précise que l'on veut rechercher des noms de fichier et de répertoire contenant la chaîne passwd, i.e.
-name '*passwd*'
Donc ici,il faut utiliser l'apostrophe ("'") ainsi que les symboles étoiles ("*") pour spécifier n'importe quels caractères qui précedent et qui suivent le chaîne de caractères passwd. Si l'on avait voulu rechercher exactement la chaîne de caractères passwd, on aurait omis les apostrophes ("'") et les étoiles ("*").
Ensuite, on spécifie l'action à prendre si l'on trouve, soit d'afficher les noms du fichier ou du répertoire en question. On peut aussi prendre d'autres actions comme exécuter une commande qui sera appliquée sur le fichier ou le répertoire trouvé.
On voit donc que la commande find est très puissante si l'on sait bien l'utiliser. On peut spécifier, par exemple, de faire une recherche seulement sur les noms de répertoire contenant la chaîne default dans le répertoire /etc. On le fait comme suit:
[berube@gut
berube]$ find /etc -type d -name '*default*' -print
/etc/default
find:
/etc/default: Permission denied
find:
/etc/httpd/conf/ssl.crl: Permission denied
find: /etc/httpd/conf/ssl.crt: Permission denied
find: /etc/httpd/conf/ssl.csr: Permission denied
find: /etc/httpd/conf/ssl.key: Permission denied
find: /etc/httpd/conf/ssl.prm: Permission denied
find:
/etc/autorpm.d: Permission denied
[berube@gut berube]$
Donc -type d permet de dire à la commande find de me trouver les répertoires (d) dont le nom contient default. Si l'on voulait spécifier de faire la recherche seulement sur les fichiers, on aurait mis -type f.
Ø
ln
La commande ln permet de créer des liens strict et symbolique. On a vu, dans le système de fichiers, la différence entre les deux. On utilisera très souvent les liens symboliques. On doit alors spécifier l'option -s et la commande fonctionne comme la commande cp. Voici un exemple simple:
[berube@gut berube]$ ln -s tarte pommes
[berube@gut berube]$
Donc, on veut que le nom pommes pointe sur le nom de fichier tarte. Enfin on peut aussi faire un lien symbolique vers un nom de répertoire.
Ø
ls
La commande ls permet de faire la liste des fichiers et des répertoires. Il existe différentes options soient -a pour voir les fichiers débutants par un point, -l pour voir les permissions, propriétaires, la dimension, etc. des fichiers, et -t pour spécifier que l'on affiche les fichiers par ordre chronologique, i.e. du plus récent vers le plus vieux. Donc sans l'option -t, la commande ls va afficher les fichiers en ordre alphanumérique. Voyons un exemple où l'on utilise la commande ls avec l'option -l.
[berube@gut
rc.d]$ ls -l
total
30
drwxr-xr-x 2 root
root 1024 Aug 9 13:48 init.d
-rwxr-xr-x 1 root
root 2859 Aug 7
2000 rc
-rwxr-xr-x 1 root
root 933 Sep 30 1999 rc.local
-rwxr-xr-x 1 root
root 16948 Aug 18 2000 rc.sysinit
drwxr-xr-x 2
root root 1024 Apr 4 07:48
rc0.d
drwxr-xr-x 2
root root 1024 Apr 4 07:48
rc1.d
drwxr-xr-x 2
root root 1024 Apr 4 07:48
rc2.d
drwxr-xr-x 2
root root 1024 Apr 4 07:48
rc3.d
drwxr-xr-x 2
root root 1024 Apr 4 07:48
rc4.d
drwxr-xr-x 2
root root 1024 May 8 13:29
rc5.d
drwxr-xr-x 2
root root 1024 Apr 29 09:21 rc6.d
[berube@gut rc.d]$
La commande affiche donc les permissions, le nombre de lien strict, le propriétaire du fichier, le groupe auquel le fichier appartient, la dimension en octets, la date de modification ainsi que le nom du fichier ou le nom du répertoire. On a déjà vu cette commande en détail dans le système de fichiers. Si ll'on ajoute l'option -a, on aura 2 lignes de plus au début. Soit ceci:
[berube@gut
rc.d]$ ls -al
total
35
drwxr-xr-x 10
root root 1024 Mar 31 07:01 .
drwxr-xr-x 44
root root 4096 Aug 10 11:38 ..
drwxr-xr-x 2
root root 1024 Aug 9 13:48
init.d
-rwxr-xr-x 1
root root 2859 Aug 7
2000 rc
-rwxr-xr-x 1
root root 933 Sep 30 1999
rc.local
-rwxr-xr-x 1
root root 16948 Aug 18 2000
rc.sysinit
drwxr-xr-x 2
root root 1024 Apr 4 07:48
rc0.d
drwxr-xr-x 2
root root 1024 Apr 4 07:48 rc1.d
drwxr-xr-x 2
root root 1024 Apr 4 07:48
rc2.d
drwxr-xr-x 2
root root 1024 Apr 4 07:48
rc3.d
drwxr-xr-x 2
root root 1024 Apr 4 07:48
rc4.d
drwxr-xr-x 2
root root 1024 May 8 13:29
rc5.d
drwxr-xr-x 2
root root 1024 Apr 29 09:21 rc6.d
[berube@gut rc.d]$
On voit donc les répertoires . et .. .
Enfin, si l'on utilise l'option -t, on aura ceci:
[berube@gut rc.d]$ ls -alt
total 35
drwxr-xr-x 44
root root 4096 Aug 10 11:38 ..
drwxr-xr-x 2
root root 1024 Aug 9 13:48
init.d
drwxr-xr-x 2
root root 1024 May 8 13:29
rc5.d
drwxr-xr-x 2
root root 1024 Apr 29 09:21 rc6.d
drwxr-xr-x 2
root root 1024 Apr 4 07:48
rc0.d
drwxr-xr-x 2
root root 1024 Apr 4 07:48
rc1.d
drwxr-xr-x 2
root root 1024 Apr 4 07:48
rc2.d
drwxr-xr-x 2
root root 1024 Apr 4 07:48
rc3.d
drwxr-xr-x 2
root root 1024 Apr 4 07:48
rc4.d
drwxr-xr-x 10
root root 1024 Mar 31 07:01 .
-rwxr-xr-x 1
root root 16948 Aug 18 2000
rc.sysinit
-rwxr-xr-x 1
root root 2859 Aug 7 2000 rc
-rwxr-xr-x 1 root
root 933 Sep 30 1999 rc.local
[berube@gut rc.d]$
On voit donc que la commande affiche les fichiers dont la date de modification passe de la plus récente vers la moins récente.
Ø
man
La commande man ("manual") permet de connaître l'utilisation d'une commande Unix avec toutes ces options possibles et souvent des exemples plus concrets. Elle peut aussi servir pour connaître la syntaxe de certains fichiers de système, par exemple celle du fichier /etc/passwd. On fera ceci:
[berube@gut berube]$ man 5 passwd
PASSWD(5)
File formats PASSWD(5)
NAME
passwd -
password file
DESCRIPTION
Passwd is a
text file, that contains a list of the sys
tem's
accounts, giving for each account some useful infor
mation
like user ID, group ID, home directory, shell, etc.
Often it
also contains the encrypted
passwords for each
account. It should
have general read permission
(many
utilities, like ls(1) use it
to map user IDs to
user
names),
but write access only for the superuser.
In the good old days there was no great problem
with this
general read permission. Everybody could read
the
encrypted passwords, but
the hardware was too slow to
crack a
well-chosen password, and
moreover, the basic
assumption used to be that of a friendly user-community.
These
days many people run some version
of the shadow
:
Ici on a spécifié 5 pour indiquer à la commande man de consulter la section 5 des pages de manuel. Si l'on ne spécifiait rien, on aurait eu la description de la commande passwd qui permet de changer de mot de passe.
[berube@gut berube]$ man passwd
PASSWD(1) User utilities PASSWD(1)
NAME
passwd -
update a user's authentication tokens(s)
SYNOPSIS
passwd [-k]
[-l] [-u [-f]] [-d] [-S] [username]
DESCRIPTION
Passwd
is used to update a user's authentication token(s).
Passwd
is configured to work through the Linux-PAM
API.
Essentially, it initializes itself as a "passwd"
service
with
Linux-PAM and utilizes configured password modules to
authenticate and then update a user's password.
A simple
entry in the Linux-PAM configuration file for
this
service would be:
#
:
Une particularité pour exprimer si une option est facultative, on l'a mettra entre crochets ([]). Pour naviguer dans une page de manuel qui ne s'affiche pas sur une seule page-écran, on doit utiliser la barre d'espacement pour avancer d'une page ou sur la lettre b pour revenir à la page précédente. Si l'on veut quitter la page de manuel en cours de route, on tape q pour quitter.
Dans une page de manuel, si une commande a des relations avec d'autres commandes, la page de manuel en fera référence. Par exemple, si l'on veut obtenir de l'information sur la commande man et voir quelles commandes dépendent de celle-ci, on verra vers la fin de cette page de manuel ceci:
SEE ALSO
apropos(1),
whatis(1), less(1), groff(1).
BUGS
:
On voit donc ci-dessus que la commande man a des relations avec les commandes apropos, whatis, less et groff. Aussi, après chaque commande on retrouve un chiffre entre parenthèses qui indique la section correspondante dans les pages de manuel. Voici la liste des sections les plus importantes que l'on retrouvent sur Linux:
|
Section |
Référence |
|
1 |
Commandes Unix que toutes et tous peuvent utiliser |
|
2 |
Librairies de système |
|
3 |
Autres librairies de système |
|
5 |
Fichiers de configuration |
|
8 |
Commandes d'administration de système |
Ø
mkdir
La commande mkdir permet de créer un répertoire s'il n'existe pas. On peut aussi utiliser l'option -p pour créer un répertoire même si son répertoire parent n'existe pas. Par exemple, si l'on veut créer le répertoire /tmp/tarte/pommes mais que le répertoire /tmp/tarte n'existe pas, on devrait normalement faire ceci:
[berube@gut berube]$ mkdir /tmp/tarte
[berube@gut berube]$ mkdir /tmp/tarte/pommes
[berube@gut berube]$
Si on essaie de le créer, on aura le message suivant:
[berube@gut berube]$ mkdir /tmp/tarte/pommes
mkdir: cannot create directory `/tmp/tarte/pommes': No
such file or directory
[berube@gut berube]$
Ø
mv
La commande mv ("move") permet de renommer un fichier. Tout comme la commande cp, on peut utiliser l'option -i pour éviter d'écraser le contenu d'un fichier. Donc, son utilisation est similaire à la commande cp.
Ø
ps
La commande ps permet de voir la liste des processus d'une machine Unix. Dans le cadre du cours, vous aurez à utiliser cette commande lorsque vous voudrez vous assurer qu'un processus que vous avez démarré est bien présent dans la machine. Il existe différentes options que l'on peut utiliser avec cette commande. Certaines options permettent de savoir combien de mémoire un processus utilise ainsi que le pourcentage d'utilisation de l'UCT ("cpu"). Les options qui sont utilisées le plus souvent sont, -auxw et -ef. Comme un exemple vaut mille mots, voici deux exemples avec ces options.
Options -auxw
C'est l'option qui permet de voir, entre autres, le pourcentage d'utilisation de l'UCT et de la mémoire par processus, les dimensions virtuelle et physique de la mémoire par processus, ainsi que le temps UCT ("cpu") que ce processus a utilisé. Voici un exemple:
[berube@gut dict]$ ps -auxw | more
USER PID
%CPU %MEM VSZ RSS TTY
STAT START TIME COMMAND
root
1 0.0 0.0 1324 76 ?
S Apr26 0:05 init [5]
root
2 0.0 0.0 0 0 ?
SW Apr26 0:08 [kflushd]
root
3 0.0 0.0 0 0 ?
SW Apr26 0:19 [kupdate]
root
4 0.0 0.0 0 0 ?
SW Apr26 0:00 [kpiod]
root
5 0.0 0.0 0 0 ?
SW Apr26 0:23 [kswapd]
root
6 0.0 0.0 0 0 ?
SW< Apr26 0:00 [mdrecoveryd]
root
47 0.0 0.0 0 0 ?
SW Apr26 0:00 [khubd]
root
326 0.0 0.1
1384 340 ? S
Apr26 61:58 syslogd -m 0
root
336 0.0 0.0
1628 184 ? S
Apr26 1:46 klogd
rpc
351 0.0 0.0
1660 140 ? S Apr26
0:07 portmap
root
367 0.0 0.0
0 0 ? SW
Apr26 0:00 [lockd]
root
368 0.0 0.0
0 0 ? SW
Apr26 0:00 [rpciod]
rpcuser
378 0.0 0.0
1580 0 ? SW Apr26 0:00 [rpc.statd]
daemon
451 0.0 0.0
1356 56 ? S
Apr26 0:00 /usr/sbin/atd
lp
518 0.0 0.0
2360 192 ? S
Apr26 0:00 lpd Waiting
root
566 0.0 0.1
3208 336 ? S
Apr26 0:00 sendmail: accepting
connections
root
734 0.0 0.0
4224 24 ? S
Apr26 0:00 /usr/sbin/nessusd -D
root
741 0.0 0.2
1660 524 ? S
Apr26 1:52
/usr/local/psionic/portsentry/portsentry -audp
--More--
Donc on y retrouve plusieurs renseignements par processus. Voyons d'abord ce que signifie chacune des colonnes ci-dessus.
|
USER |
Usager à qui appartient le processus |
|
PID |
Numéro de processus qui lui est associé (PID: Process ID) |
|
%CPU |
Pourcentage de l'UCT utilisée par ce processus |
|
%MEM |
Pourcentage de la mémoire physique utilisée par le processus |
|
VSZ |
Mémoire virtuelle (kilooctets) utilisée par le processus (VSZ: Virtual size) |
|
RSS |
Mémoire physique (kilooctets) utilisée par le processus (RSS: Resident Set Size) |
|
TTY |
Terminal associé au processus |
|
STAT |
État du processus |
|
START |
Heure ou date de démarrage du processus |
|
TIME |
Temps UCT dépensé par le processus sous le format MM:SS, i.e. MM pour minute(s) et SS pour seconde(s) |
|
COMMAND |
Nom de la commande ou d'un démon ("daemon") de système associé et les arguments associés à ce processus. |
Sans entrer dans tous les détails, l'option -a permet de voir la liste de tous les processus du système, -u permet un affichage orienté usager, -x permet de voir les processus dont aucun terminal n'y est associé et -w permet l'affichage de plus d'information dans la colonne COMMAND.
Options -ef
Celles-ci n'affichent pas les pourcentages d'utilisation de l'UCT et de la mémoire, ainsi que les dimensions de mémoire virtuelle et physique. Par contre, elles permettent de connaître le numéro d'un processus parent. Il est aussi possible avec ces options d'en ajouter et d'obtenir l'équivalent de -auxw. Donc, voici un exemple:
[berube@gut berube]$ ps -ef | more
UID
PID PPID C STIME TTY TIME CMD
root
1 0 0 Apr26 ? 00:00:05
init [5]
root
2 1 0 Apr26 ? 00:00:08
[kflushd]
root
3 1 0 Apr26 ? 00:00:19
[kupdate]
root
4 1 0 Apr26 ? 00:00:00
[kpiod]
root
5 1 0 Apr26 ? 00:00:23 [kswapd]
root
6 1 0 Apr26 ? 00:00:00
[mdrecoveryd]
root
47 1 0 Apr26 ? 00:00:00 [khubd]
root
326 1 0 Apr26 ? 01:01:58 syslogd -m 0
root
336 1 0 Apr26 ? 00:01:46 klogd
rpc
351 1 0 Apr26 ? 00:00:07 portmap
root
367 1 0 Apr26 ? 00:00:00 [lockd]
root
368 367 0 Apr26 ? 00:00:00 [rpciod]
rpcuser 378
1 0 Apr26 ? 00:00:00 [rpc.statd]
daemon 451 1
0 Apr26 ? 00:00:00
/usr/sbin/atd
lp
518 1 0 Apr26 ? 00:00:00 lpd Waiting
root
566 1 0 Apr26 ? 00:00:00 sendmail: accepting connections
root
734 1 0 Apr26 ? 00:00:00 /usr/sbin/nessusd -D
--More--
Donc, voici ce que signifie les colonnes suivantes:
|
PPID |
Numéro du processus parent auquel est associé le processus (PPID: Parent Process ID) |
|
C |
Paramètre interne pour la gestion des processus qui n'est plus utilisé |
|
STIME |
Même signification que DATE ci-dessus |
|
TIME |
Temps UCT dépensé par le processus mais sous le format HH:MM:SS |
|
CMD |
Même signification que COMMAND ci-dessus |
Donc l'option -e permet de voir la liste complète de tous les processus et l'option -f permet d'afficher le PID, le PPID, le TTY ainsi que la commande ou le "démon" avec les arguments qui sont associés au processus.
Ø
rm
La commande rm ("remove") permet d'effacer un fichier. Il y a quelques options intéressantes qu'il est bon de connaître. Si l'on utilise l'option -i, vous devez confirmer avant de détruire un fichier. Voici un exemple simple:
[berube@gut berube]$ rm -i http.htm
rm: remove `http.htm'? y
[berube@gut berube]$
Donc vous devez répondre y ("yes") pour confirmer que vous voulez bien détruire le fichier. Tout autre caractère sera pris comme un refus de détruire le fichier.
Une autre option intéressante, c'est -f. Il arrive parfois que même si l'on n'a pas spécifié l'option -i, qu'il faille confirmer la destruction d'un fichier. Un exemple sera un fichier qui aurait été créé dans votre répertoire mais qui ne vous appartient pas. Donc, l'option -f force la commande à essayer de détruire le fichier sans demande de confirmation. Voici un exemple:
[berube@gut berube]$ rm toto.cfg
rm: remove write-protected file `toto.cfg'?
Donc, on voit que l'on doit confirmer pour effacer le fichier puisqu'il n'appartient pas à l'usager qui essaie de détruire le fichier. Avec l'option -f, il sera effacé:
[berube@gut berube]$ rm -f toto.cfg
[berube@gut berube]$
Enfin, l'option -r qui permet de détruire récursivement des fichiers et répertoires. On l'utilise généralement pour détruire un répertoire dont il contient des fichiers et d'autres répertoires. Par exemple, si l'on a un répertoire test qui contient des fichiers, on fera ceci:
[berube@gut tmp]$ rm -r test
[berube@gut tmp]$
Si l'on n'avait pas utilisé -r, on aurait eu le message d'erreur suivant:
[berube@gut tmp]$ rm test
rm: `test' is a directory
[berube@gut tmp]$
On peut aussi l'utiliser pour détruire le contenu d'un répertoire comme suit:
[berube@gut tmp]$ rm -r *
[berube@gut tmp]$
Ø
rmdir
La commande rmdir permet de détruire un répertoire à condition que son contenu soit vide. S'il ne l'est pas, la commande indiquera le message "Directory not empty". Voici un exemple:
[berube@gut
tata]$ rmdir toto
rmdir: toto: Directory not empty
[berube@gut tata]$
Pour être en mesure de détruire ce répertoire, il faut effacer tous les fichiers et répertoires qu'il contient. Si l'on ne veut pas détruire chaque fichier et répertoire, on peut utiliser la commande rm avec l'option -r.
Il existe l'option -p qui permet de détruire récursivement des répertoires à condition que ceux-ci ne contiennent aucun fichier. Donc, si dans le répertoire toto, il existe seulement le répertoire dir, on utilisera l'option -p comme suit:
[berube@gut
tata]$ rmdir -p toto/dir
[berube@gut tata]$
La commande a donc détruit le sous-répertoire dir dans le répertoire toto et ensuite elle a détruit toto. Donc, cette commande est équivalente à ceci:
[berube@gut
tata]$ rmdir toto/dir
[berube@gut
tata]$ rmdir toto
[berube@gut
tata]$
Ø
sed
La commande sed permet de rechercher et remplacer une chaîne de caractères présente dans un fichier et d'afficher le tout à l'écran ("standard output"). Pour bien comprendre l'utilisation de la commande sed, considérons le petit texte suivant:
COMMANDE:
Stream EDitor
Le
texte suivant permet de mieux comprendre l'utilisation de la commande
COMMANDE. COMMANDE permet de remplacer
une chaîne de caractères sans avoir à éditer le fichier. Donc COMMANDE est un outil puissant qu'il
est bon de connaître lorsque l'on veut utiliser la puissance du mode commande
d'Unix.
Donc on veut que dans le texte ci-dessus, on puisse remplacer COMMANDE par le mot sed. Voici comment il faut le faire:
[berube@gut tmp]$ sed 's/COMMANDE/sed/g' texte
sed:
Stream EDitor
Le
texte suivant permet de mieux comprendre l'utilisation de la commande sed. sed permet de remplacer une chaîne de
caractères sans avoir à éditer le fichier.
Donc sed est un outil puissant qu'il est bon de connaître lorsque l'on
veut utiliser la puissance du mode commande d'Unix.
[berube@gut tmp]$
Entre les apostrophes ("'"), on a écrit des instructions qui peuvent paraître un peu cryptiques. Le s signifie "substitue", donc substituer la chaîne de caractères COMMANDE pour sed. Il faut mettre les "/" pour délimiter la chaîne d'origine et celle de substitution. Enfin, le g signifie que si la chaîne d'origine apparaît plus d'une fois sur une même ligne, on la remplace tant et aussi longtemps qu'elle apparaît.
Si l'on avait voulu afficher seulement les lignes qui contenaient la chaîne de caractères COMMANDE, on aurait alors utilisé l'option -n. Donc le résultat aurait été ceci:
[berube@gut tmp]$ sed -n 's/COMMANDE/sed/p' texte
sed: Stream EDitor
sed. COMMAND permet de remplacer une chaîne de
caractères sans avoir
à
éditer le fichier. Donc sed est un
outil puissant qu'il est bon
[berube@gut tmp]$
On doit cependant spécifier le paramètre p pour que les lignes soient affichées. Si l'on avait voulu juste faire une recherche de lignes ayant COMMANDE, on aurait alors fait ceci:
[berube@gut
tmp]$ sed -n '/COMMANDE/p' texte
COMMANDE: Stream EDitor
COMMANDE. COMMANDE permet de
remplacer une chaîne de caractères sans avoir
à
éditer le fichier. Donc sed est un
outil puissant qu'il est bon
[berube@gut tmp]$
Enfin, il est possible d'écrire des programmes sed. Il faut alors appeler la commande avec l'option -f et le nom du programme. Voici un exemple de programme sed:
[berube@gut
tmp]$ cat sed.prog
s/COMMANDE/sed/g
/sed:/ i\
commande
Unix
[berube@gut
tmp]$
Donc, on remplace COMMANDE par sed et aussi, lorsqu'une ligne contient sed:, on insère une ligne juste avant, soit commande Unix. Le résultat est le suivant.
[berube@gut tmp]$ sed -f sed.prog texte
commande Unix
sed: Stream EDitor
Le
texte suivant permet de mieux comprendre l'utilisation de la commande
sed. sed permet de remplacer une chaîne de
caractères sans avoir
à
éditer le fichier. Donc sed est un outil
puissant qu'il est bon
de
connaître lorsque l'on veut utiliser la puissance du mode commande
d'Unix.
[berube@gut tmp]$
Finalement on peut utiliser la commande sed avec un "pipe" pour traiter le résultat d'une commande. Par exemple, on aurait pu faire ceci:
[berube@gut
tmp]$ cat texte | sed -f sed.prog
commande Unix
sed: Stream EDitor
Le
texte suivant permet de mieux comprendre l'utilisation de la commande
sed. sed permet de remplacer une chaîne de
caractères sans avoir
à
éditer le fichier. Donc sed est un
outil puissant qu'il est bon
de
connaître lorsque l'on veut utiliser la puissance du mode commande
d'Unix.
[berube@gut tmp]$
Ø
tail
La commande tail permet d'afficher les dernières lignes d'un fichier ou du résultat d'une commande. Par défaut, il affichera les 10 dernières lignes. Si l'on veut afficher le nombre de lignes désirées, on utilise l'option -n où n est le nombre de lignes à afficher. Donc tail -20 affichera les 20 dernières lignes d'un fichier. Voici un exemple où l'on affiche la dernière ligne d'un fichier:
[berube@gut
tmp]$ tail -1 /etc/passwd
cprt:x:500:500:Claude Prevost:/home/cprt:/bin/bash
[berube@gut tmp]$
On utilise souvent la commande tail afin de voir les dernières lignes pour un fichier de journaux ("logs"). Par exemple, si l'on veut voir la liste des dernières transactions de courrier électronique, on fera ceci:
[root@gut
tmp]# tail /var/log/maillog
Aug 20 00:03:50 gut sendmail[3344]: f7K40Q303344:
from=root, size=5681, class=0, nrcpts=1, msgid=<200108200400.f7K40Q303344@gut.cti.ulaval.ca>,
relay=root@localhost
Aug 20 00:03:51 gut sendmail[3344]: f7K40Q303344:
to=root, ctladdr=root (0/0), delay=00:03:25, xdelay=00:00:01, mailer=local,
pri=35681, dsn=2.0.0, stat=Sent
[root@gut tmp]#
Dans le cas ci-dessus, on a que deux lignes dans ce fichier. S'il y en avait eu dix et plus, seules les 10 dernières l'auraient été.
Une autre utilisation de la commande tail, c'est de pouvoir afficher au fur et à mesure les lignes qui s'ajoutent dans un fichier. Par exemple, si l'on a un serveur de courrier et que l'on veut voir passer les transactions de courrier qui sont en train d'être traitées, on va utiliser l'option -f. À ce moment, la commande tail ne retourne pas l'invite ("prompt") Unix. Il faut faire Ctrl-C pour arrêter la commande.
[root@gut
tmp]# tail -f /var/log/maillog
Aug 20 00:03:50 gut sendmail[3344]: f7K40Q303344:
from=root, size=5681, class=0, nrcpts=1,
msgid=<200108200400.f7K40Q303344@gut.cti.ulaval.ca>, relay=root@localhost
Aug 20 00:03:51 gut sendmail[3344]: f7K40Q303344:
to=root, ctladdr=root (0/0), delay=00:03:25, xdelay=00:00:01, mailer=local,
pri=35681, dsn=2.0.0, stat=Sent
Ø
tar
Lors de la remise des travaux, vous devrez fournir un fichier qui contient tous les fichiers que vous aurez créés pour ceux-ci. On utilise la commande tar pour archiver ces fichiers. Voici un exemple simple qui permet de générer un fichier tar pour un répertoire qui contient des fichiers et des sous-répertoires:
[berube@gut
travail1]$ tar cvf /tmp/travail1.tar .
./
./repertoire/
./repertoire/fichier1.txt
./repertoire/fichier2.txt
./manuel
./sources/
./sources/prog.pl
[berube@gut travail1]$
Donc, cvf sont les options utilisées par la commande tar. Le "c" permet de créer un fichier d'archivage, "v" pour afficher les fichiers et répertoires qui sont mis dans le fichier d'archivage, et enfin "f" permet de spécifier le fichier d'archivage. Le "." permet de dire à la commande tar de prendre les fichiers et répertoires du répertoire courant. Pour voir le contenu de le fichier d'archivage, on fait ceci:
[berube@gut
travail1]$ tar tvf /tmp/travail1.tar
drwxr-xr-x berube/hacker 0 2001-08-20 07:36:09 ./
drwxr-xr-x berube/hacker 0 2001-08-20 07:36:54 ./repertoire/
-rw-r--r-- berube/hacker 967 2001-08-20 07:36:48 ./repertoire/fichier1.txt
-rw-r--r-- berube/hacker 516 2001-08-20 07:36:54 ./repertoire/fichier2.txt
-rw-r--r-- berube/hacker 52 2001-08-20 07:35:50 ./manuel
drwxr-xr-x berube/hacker 0 2001-08-20 07:36:27 ./sources/
-rwxr-xr-x berube/hacker 34 2001-08-20 07:36:27 ./sources/prog.pl
[berube@gut travail1]$
Donc, l'option t permet de voir le contenu (t: table of content) du fichier travail1.tar. Si l'on veut extraire les fichiers, on se positionnera dans un autre répertoire, à moins que l'on veuille écraser le contenu du répertoire courant, on fera ceci:
[berube@gut
travail1]$ cd /tmp
[berube@gut
/tmp]$ mkdir travail1
[berube@gut
/tmp]$ cd travail1
[berube@gut
travail1]$ tar xvf /tmp/travail1.tar
./
./repertoire/
./repertoire/fichier1.txt
./repertoire/fichier2.txt
./manuel
./sources/
./sources/prog.pl
[berube@gut travail1]$
On a alors une copie de le fichier d'archivage que l'on a créée.
Il est possible d'extraire un fichier d'un fichier d'archivage comme suit:
[berube@gut
travail1]$ tar xvf /tmp/travail1.tar ./repertoire/fichier1.txt
./repertoire/fichier1.txt
[berube@gut travail1]$
Donc seul le fichier fichier1.txt qui est dans le répertoire repertoire sera extrait. Il faut cependant spécifier ./repertoire/fichier1.txt sinon il ne trouve pas le fichier. Donc, si l'on avait utilisé la commande en ne spécifiant pas le chemin complet pour fichier1.txt, on aurait eu ceci:
[berube@gut
travail1]$ tar xvf /tmp/travail1.tar fichier1.txt
tar: fichier1.txt: Not found in archive
tar: Error exit delayed from previous errors
[berube@gut travail1]$
Donc, avant d'extraire un fichier ou même un répertoire, utilisez l'option t pour voir le contenu de le fichier d'archivage et ensuite vous serez en mesure d'extraire le bon fichier ou répertoire.
Ø
umask
La commande umask permet de fixer les permissions par défaut d'un fichier Unix. Par exemple, si l'on veut qu'un fichier soit toujours créé avec les permissions de lecture, écriture pour le propriétaire du fichier, de lecture pour le groupe auquel appartient le fichier et aucune permission pour les autres, on utilisera la commande comme suit:
[berube@gut
travail1]$ umask 027
[berube@gut
travail1]$ touch fichier.test
[berube@gut
travail1]$ ls -l fichier.test
-rw-r----- 1
berube hacker 0 Aug 20 07:49 fichier.test
[berube@gut travail1]$
Donc on voit ici que le fichier fichier.test a pour permission celle que l'on a demandée. Donc, la commande umask s'utilise comme le complément de la commande chmod que l'on a vue ci-dessus. Pour bien comprendre, on représente le 027 comme trois nombres de trois bits chacun. Donc, pour les permissions, on peut le voir en utilisant le tableau ci-dessus.
|
Octal |
Binaire |
Permissions |
|
0 |
0 |
rwx |
|
1 |
1 |
rw- |
|
2 |
10 |
r-x |
|
3 |
11 |
r-- |
|
4 |
100 |
wx |
|
5 |
101 |
-w- |
|
6 |
110 |
--x |
|
7 |
111 |
--- |
Le 0 permet de dire que les permissions du propriétaire du fichier seront rwx si c'est un fichier exécutable ou rw- si c'est un fichier texte. Le 2 permet de dire que les permissions sur le groupe auquel appartient le fichier seront r-x si c'est un fichier exécutable ou r-- si c'est un fichier texte. Enfin, pour les autres, il n'y aura pas de permissions sur le fichier qu'il soit exécutable ou non.
8.Daemons
Il existe plusieurs "daemons" qui s'exécutent dans une machine Linux. Dans le cadre de du cours "Implantation d'un site Internet", on s'attardera plus en détails sur quelques-uns, soient plus spécifiquement ceux ayant rapport aux serveurs Internet. Donc un "daemon" est un processus qui écoute sur un numéro de port TCP/IP ou qui surveille le système, et qui répond aux requêtes qu'il reçoit. Une des caractéristiques d'un "daemon", c'est qu'il tourne en permanence dans la machine, i.e. qu'il démarre lorsque Linux démarre et meurt lorsque Linux meurt. On peut dire que le processus est permanent, i.e. qu'il est présent en mémoire tout le temps que la machine
Linux est en vie.
Chaque "daemon" possède une tâche précise et il faut en connaître quelques-uns pour mieux comprendre le fonctionnement d'une machine Linux. Voici une liste des principaux "daemons" que l'on retrouve sur Linux:
Noyau ("kernel")
· kflushd
· kupdate
· kpiod
· kswapd
· khubd
· klogd
Serveur pour journaliser les messages des "daemons" et autres applications
· syslogd
Serveur responsable de faire le lien entre les RPCs et les numéros de port
TCP/IP
· portmap
Serveur de gestion des tâches en différées
· atd
Serveur de courrier
· sendmail (optionnel)
· qpopper (optionel)
· imapd (optionnel)
Serveur d'impression
· lpd (optionnel)
Serveur de gestion des tâches répétitives
· crond
Serveur NFS
· rpc.statd
· rpc.rquotad (optionnel)
·
rpc.mountd
(optionnel)
·
rpc.lockd,
lockd (optionnel)
· nfsd (optionnel)
Serveur Web
· httpd (optionnel)
Serveur de noms - DNS
· named (optionnel)
Serveur LDAP
· slpad (optionnel)
Serveur Windows
· smbd
Les "daemons" ci-dessus qui débutent par un k, dépendent du noyau ("kernel") de Linux. En effet, ils sont prioritaires car ils doivent assurer le bon fonctionnement du système Linux. kflushd et kupdate permettent de gérer les entrées-sorties sur le disque. kupdate va vérifier à toutes les cinq secondes si certains "buffers" doivent être envoyés sur le disque et si c'est le cas, kflushd va s'occuper de les écrire. kpiod et kswapd permettent la gestion des pages en mémoire. Un programme qui s'exécute peut dans certains cas ne pas utiliser certaines portions de mémoire qui ne sont pas
vraiment utilisées par celui-ci. À ce moment, la partie du code qui n'est pas requise en mémoire sera mise sur la partition swap. Donc kswapd dit, qui se réveille à chaque seconde, va vérifier si c'est le cas, et donc demandera à kpiod de sortir ces pages et de les mettre sur la partition swap. Ceci se produira aussi si la mémoire physique n'est pas assez grande pour contenir l'ensemble des processus, donc on sortira et l'on entrera des pages en mémoire. klogd s'occupe d'intercepter les messages du noyau ("kernel") et de les "journaliser" dans les journaux ("logs") du système.
Dans la liste ci-dessus, on a donc une série de "daemons" qui ont des tâches bien précises, soient pour la gestion du noyau("kernel"), la gestion des messages générés par les "daemons" et certaines applications (syslogd), serveur de courrier, etc. Dans le cadre du cours on insistera sur ceux ayant rapport au courrier électronique, au serveur Web ainsi qu'au serveur de noms ("DNS").